

欢迎来到人工智能革命日益改变日常任务和互动的时代。Google Gemma站在这场革命的前沿,为全球的开发人员和研究人员提供了无与伦比的能力。在本指南中,我们将探讨如何在本地发挥Gemma的潜力,解锁其改变项目和应用的潜力。此外,我们将提供关于如何运行Google Gemma模型的详细说明,确保您可以有效地利用其先进的人工智能功能来满足您的特定需求,无论您是在进行创新研究还是开发尖端应用。
目录
什么是Google Gemma?
Google Gemma不仅仅是另一个AI模型;它是由Google和DeepMind富有远见的头脑开发的改变游戏规则的产品。受到开创性的Gemini模型的启发,Gemma在AI创新和性能方面树立了新的标准。具有灵活的2B和强大的7B参数大小两个变体,Gemma适用于各种计算需求和场景,使其成为广泛应用的多功能工具。
为什么Gemma突出?
Gemma相对于其他AI模型(如Mistral 7B和DeciLM 7B)的优势在于其卓越的效率和准确性。配备了增强适应性和响应性的指令模型,Gemma在理解和执行复杂任务方面表现出色。Gemma的总令牌词汇量为256k。
使用Ollama本地运行Gemma
要在本地运行Gemma,您需要设置Ollama,这是一个简化AI模型部署的平台。以下是一份逐步指南:
第一步:从下载Ollama开始
- 点击此链接前往Ollama网站:下载Ollama。
- 选择版本0.1.26或更新版本,以确保它与Google Gemma无缝配合。
- 选择与您计算机操作系统相匹配的下载选项(无论是Windows、macOS还是Linux)。
第二步:安装过程
- 对于Windows用户:
- 只需双击您下载的 .exe 文件,然后按照屏幕上出现的提示进行操作。
- 对于 macOS 和 Linux 用户:
- 首先,打开终端。
- 使用终端导航到您保存下载文件的文件夹。
- 键入 chmod +x <filename> 来授予文件执行权限,将 <filename> 替换为您下载文件的名称。
- 现在,键入 ./<filename> 并按Enter键开始安装。
第三步:确认Ollama的安装
- 打开一个终端窗口或命令提示符。
- 键入 ollama –version 并按Enter键。
- 如果一切顺利,您将看到已安装的Ollama版本显示出来,确认安装成功。
就是这样!通过这些步骤,您已经准备好利用Ollama探索Google Gemma的功能了。
对于Windows,由于证书问题,它还处于早期阶段,存在恶意软件警告,您可以将其添加到白名单中。我也是Ollama的贡献者,所以我们正在努力尽快解决这个问题。
Gemma的系统要求
确保您的系统满足以下要求,以实现Gemma的最佳性能:
- 处理器:多核 CPU(Intel i5/i7/i9 或 AMD 等效)
- 内存:至少需要8GB RAM来运行7B模型,16GB RAM来运行13B模型,以及32GB RAM来运行33B模型。
- 存储:至少需要20GB的SSD空间
- 操作系统:Windows、macOS 或 Linux 的最新版本
如何使用Ollama在本地运行Google Gemma模型
安装完Ollama并准备好您的系统后,您可以在本地启动Gemma。
第一步:启动Gemma
首先,打开你的终端或命令提示符。要使用Gemma,你需要输入特定的命令,具体取决于你打算使用的Gemma模型大小,默认情况下在运行时会下载7B模型,命令为:ollama run gemma
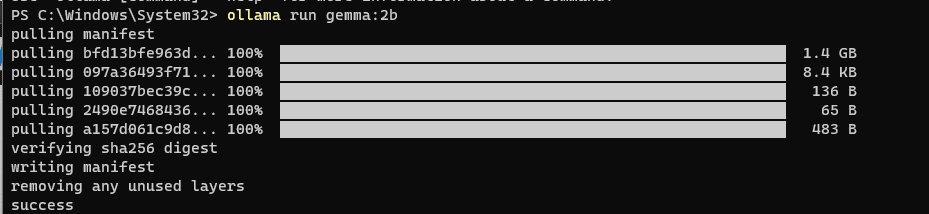
对于2B模型:
ollama run gemma:2b对于7B模型:
ollama run gemma:7b
步骤2:设置模型
- 这些命令的初始运行会提示 Ollama 下载指定的 Gemma 模型。下载时间将根据您的互联网连接而异。
- 下载完成后,Gemma 将被设置好,准备就绪。
第三步:与 Gemma 互动
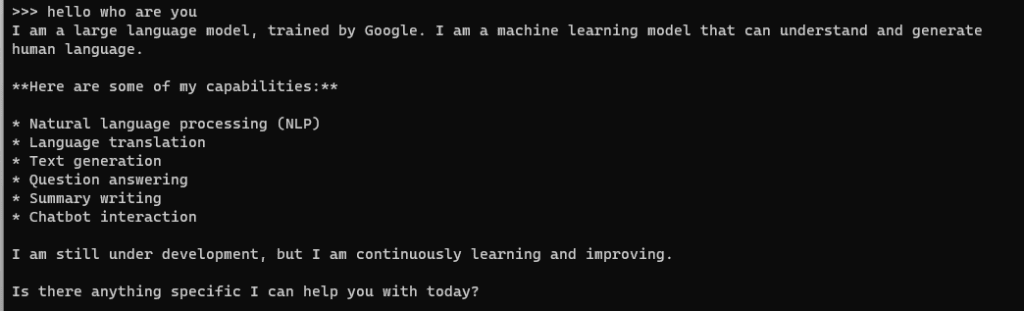
有了 Gemma 运行起来,你现在可以开始与它互动了。无论你是想处理文本、分析数据还是执行其他任务,都可以将你的指令直接输入到通过 Ollama 托管 Gemma 的终端中。
以下是一个关于查询 Gemma 的快速指南:
echo "Your query here" | ollama run gemma:2b
简单地将 “Your query here” 替换为您想要询问或让 Gemma 完成的任务。

就像这样,您已经准备好通过Ollama探索Gemma为您所做的一切。