Welcome to the era of artificial intelligence revolutionizing everyday tasks and interactions. Google Gemma stands at the forefront of this revolution, offering unparalleled capabilities to developers and researchers worldwide. In this guide, we’ll explore how you can harness the power of Gemma locally, unlocking its potential to transform your projects and applications. Additionally, we will provide a detailed walkthrough on how to run the Google Gemma model, ensuring you can effectively utilize its advanced AI features for your specific needs, whether you’re working on innovative research or developing cutting-edge applications.
Table of Contents
What Is Google Gemma?
Google Gemma is not just another AI model; it’s a game-changer developed by the visionary minds at Google and DeepMind. Inspired by the groundbreaking Gemini models, Gemma sets new standards in AI innovation and performance. With two variants – the nimble 2B and the robust 7B parameter sizes – Gemma caters to diverse computational needs and scenarios, making it a versatile tool for a wide range of applications.
Why Gemma Stands Out
Gemma’s superiority over other AI models like Mistral 7B and DeciLM 7B lies in its exceptional efficiency and accuracy. Equipped with instruction models that enhance adaptability and responsiveness, Gemma excels in understanding and executing complex tasks with finesse. Gemma has total 256k token vocabulary size.
Running Gemma Locally with Ollama
To run Gemma locally, you’ll need to set up Ollama, a platform that simplifies the deployment of AI models. Here’s a step-by-step guide:
Step 1: Begin with Downloading Ollama
- Head over to the Ollama website by following this link: Download Ollama.
- Choose version 0.1.26 or a newer version to ensure it works seamlessly with Google Gemma.
- Pick the download option that matches your computer’s operating system (be it Windows, macOS, or Linux).
Step 2: Installation Process
- For Windows Users:
- Simply double-click on the .exe file you’ve downloaded and follow the prompts that appear on your screen.
- For macOS and Linux Users:
- First, open the Terminal.
- Use the Terminal to navigate to the folder where you saved the downloaded file.
- Type
chmod +x <filename>to grant execution permissions to the file, replacing<filename>with the name of your downloaded file. - Now, start the installation by typing
./<filename>and hitting Enter.
Step 3: Confirming Ollama’s Installation
- Open a Terminal window or Command Prompt.
- Type
ollama --versionand press Enter. - If everything went smoothly, you’ll see the installed version of Ollama displayed, confirming the successful setup.
And there you have it! With these steps, you’re all set to explore the capabilities of Google Gemma with Ollama on your side.
For Windows, its in early stage and due to certificate issue there is malware warnings, you can whitelist that. I am also a contributor at Ollama so we are working to fix that soon.
System Requirements for Gemma
Ensure your system meets the following requirements for optimal performance of Gemma:
- Processor: Multi-core CPU (Intel i5/i7/i9 or AMD equivalent)
- Memory: You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.
- Storage: At least 20 GB of free space on an SSD
- Operating System: Recent versions of Windows, macOS, or Linux
How to Run Google Gemma Model Locally with Ollama
Once Ollama is installed and your system is ready, you can launch Gemma locally.
Step 1: Starting Up Gemma
First, open your terminal or command prompt. To use Gemma, you’ll need to enter specific commands depending on the Gemma model size you’re aiming to utilize, by default it downloads 7B model on running, ollama run gemma:
For the 2B Model:
ollama run gemma:2bFor the 7B Model
ollama run gemma:7b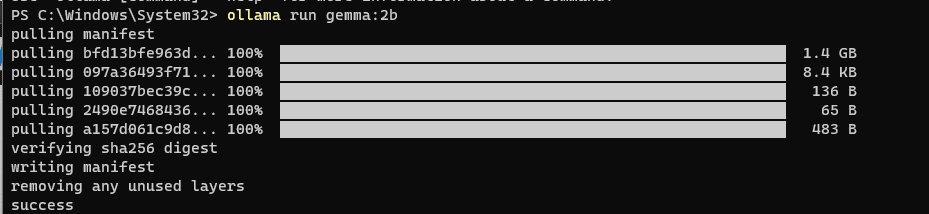
Step 2: Setting Up the Model
- The initial run of these commands prompts Ollama to download the specified Gemma model. The download time will vary based on your internet connection.
- After the download finishes, Gemma will be set up and ready for action.
Step 3: Engaging with Gemma
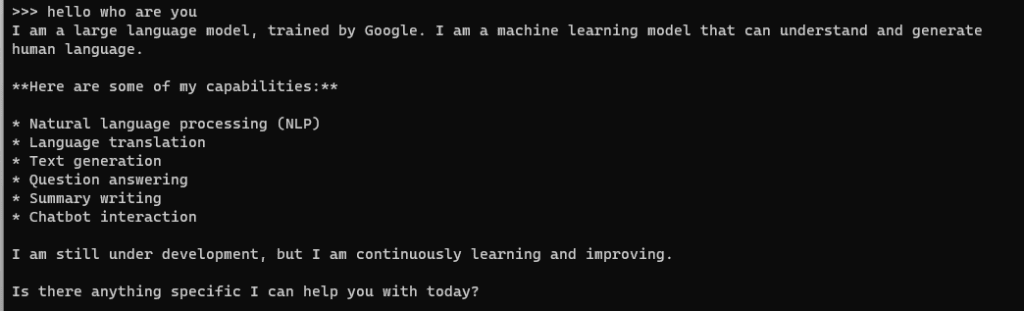
With Gemma up and running, you’re now ready to interact with it. Whether you’re looking to process text, analyze data, or carry out other tasks, you’ll input your instructions directly into the terminal hosting Gemma through Ollama.
Here’s a quick guide on querying Gemma:
echo "Your query here" | ollama run gemma:2b
Simply replace “Your query here” with whatever you’re looking to ask or have Gemma do.
And just like that, you’re all set to explore what Gemma can do for you through Ollama.
I Downloaded Google Gemma Model Locally. How Can I Infer Something with it?
You can use the above guide to install the model using Ollama and then you can use the terminal to use it or even the ollama endpoint can be useful for it.
How to run Gemma 7B Mac?
To install Gemma 7B model on mac, you can use the ‘ollama run gemma:7b’ command to download the model and install it.
What’s Gemma Gardware Requirements?
Processor: Multi-core CPU (Intel i5/i7/i9 or AMD equivalent)
Memory: You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.
Storage: At least 20 GB of free space on an SSD
Operating System: Recent versions of Windows, macOS, or Linux
How To Install Gemini 2B on Notebook?
You can use this guide in which you have to use the PyTorch to install on Notebook, How To Run Gemma with PyTorch Locally: A Step-by-Step Guide